PIDGraph
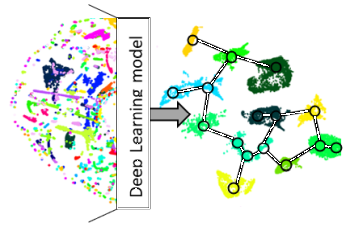
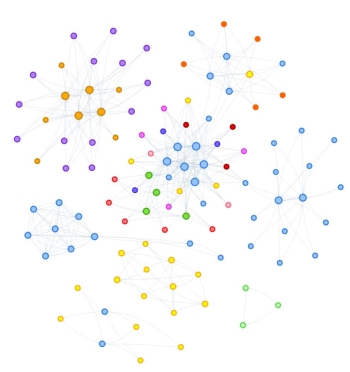
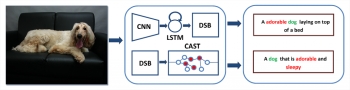
Piping and instrumentation diagrams (P&IDs) are central documents in the engineering process of chemical plants. They describe how the individual devices of such a plant are configured and interconnected. However, P&IDs of older plants are often stored on paper or crude digital formats, lacking any kind of semantic information. PIDGraph is designed to bridge that gap by extracting graph structures from P&IDs and providing functions to edit and enhance them automatically. PIDGraph brings together deep learning, computer vision and semantic technologies.